


Artificial Intelligence and Machine Learning Articles
Experiment: Figma to Replit Plugin
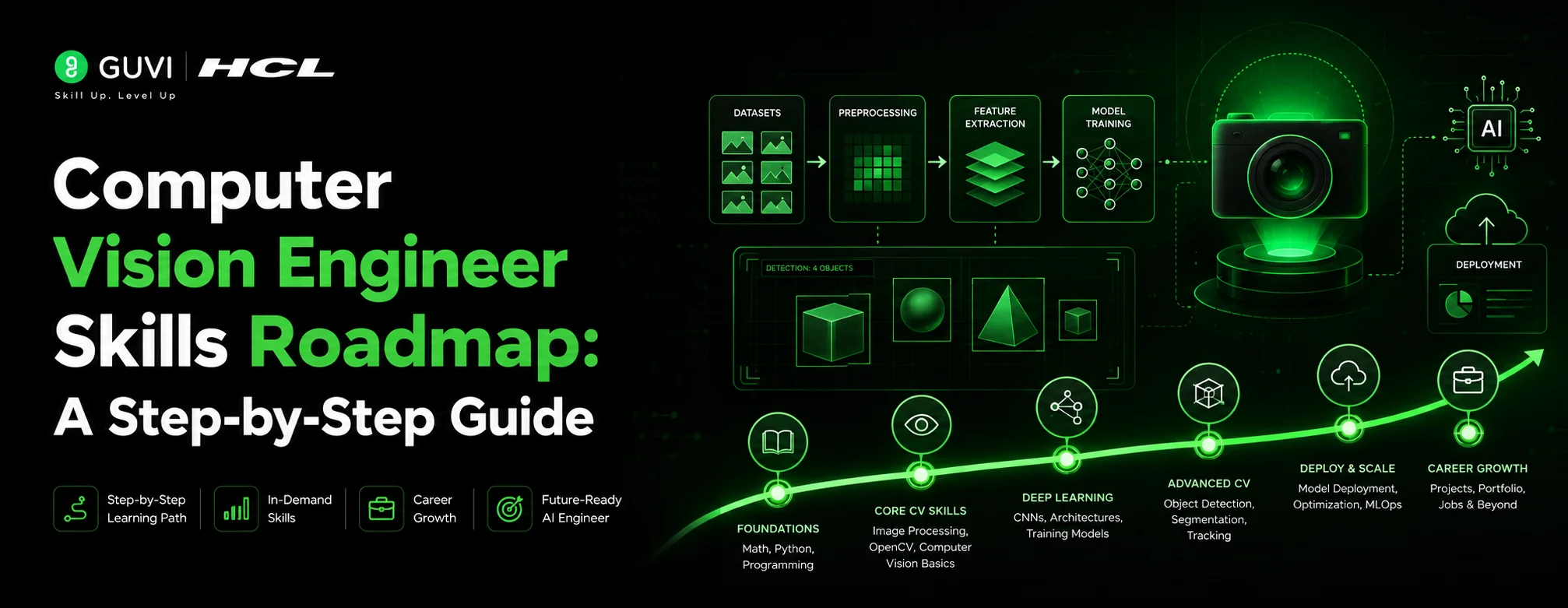
Computer Vision Engineer Skills Roadmap: A Step-by-Step Guide
What is Replit’s New Database Editor? A Beginner-Friendly Guide


Get In Touch For Details! Request More Information

Skills Required to Become a Speech Recognition Engineer in 2026
Jun 26, 2026 4 Min Read 37 Views
(Last Updated)
Table of contents
- TL;DR Summary
- What Does a Speech Recognition Engineer Actually Do?
- Core Technical Skills You Need
- Programming Languages
- Machine Learning and Deep Learning
- Signal Processing and Acoustic Modelling
- Natural Language Processing (NLP)
- ASR Frameworks and Tools
- Data Handling and Annotation
- Soft Skills That Actually Matter
- Common Mistakes Beginners Make
- Conclusion
- FAQs
- What is a Speech Recognition Engineer?
- What programming language is most important for speech recognition?
- Do I need a degree to become a Speech Recognition Engineer?
- What is acoustic modelling in speech recognition?
- What frameworks should a Speech Recognition Engineer know?
- What is Word Error Rate (WER) and why does it matter?
- How is NLP different from speech recognition?
- Can I enter this field from a software engineering background?
TL;DR Summary
A Speech Recognition Engineer builds systems that convert spoken language into text or commands. To break into this field, you need a strong foundation in machine learning, signal processing, and natural language processing, backed by programming skills in Python or C++.
Familiarity with frameworks like TensorFlow or PyTorch and hands-on experience with ASR (Automatic Speech Recognition) systems are essential. This role sits at the intersection of linguistics, AI, and software engineering, and demand for it is growing fast.
Every time you speak to Siri, ask Alexa to play a song, or dictate a message on your phone, a Speech Recognition Engineer’s work is quietly running in the background. This role is no longer niche.
As voice interfaces become standard across healthcare, automotive, and consumer tech, the demand for engineers who can build and improve speech systems is growing rapidly. If you’re thinking about entering this space, here’s what you actually need to learn.
What Does a Speech Recognition Engineer Actually Do?
Before you plan your learning path, it helps to understand what this role involves on a daily basis.
A Speech Recognition Engineer designs, trains, and optimises models that convert spoken audio into text or executable commands. This involves designing algorithms, conducting experiments, and implementing technologies that improve the accuracy and efficiency of voice-driven applications.
You’ll often work as part of a cross-functional team that includes data scientists, software engineers, and sometimes linguists. The goal is always the same: make the system understand human speech better, across accents, noise, and context.
Core Technical Skills You Need
1. Programming Languages
This is your foundation. You cannot build or train speech models without solid programming ability.
Strong programming skills in languages such as Python, C++, or Java are commonly required in speech recognition projects. Python is the most widely used because of its rich ecosystem for machine learning. C++ becomes essential when you’re working on performance-critical applications like embedded voice systems.
Start with Python. Learn C++ once you’re comfortable with the ML side of things.
2. Machine Learning and Deep Learning
Speech recognition is fundamentally a machine learning problem. You need to understand how models learn patterns from data, how to train them, and how to evaluate their performance.
Proficiency in machine learning tools like TensorFlow and PyTorch is required in 75% of speech recognition job postings.
Beyond the tools, you need to understand:
- Neural network architectures, especially RNNs and Transformers
- Transfer learning and fine-tuning pre-trained models
- Model evaluation metrics like Word Error Rate (WER)
- Techniques for handling overfitting and data imbalance
Deep learning is particularly important here. Modern ASR systems like Whisper and Wav2Vec are built entirely on deep neural networks, not classical rule-based systems.
3. Signal Processing and Acoustic Modelling
This is where speech recognition differs from most other ML roles. You’re not working with text or images, you’re working with audio.
Speech recognition engineers need expertise in signal processing, machine learning, and natural language processing. Understanding acoustic modeling and linguistic patterns enhances system accuracy.
You need to understand how to:
- Convert raw audio into spectrograms and MFCCs (Mel-Frequency Cepstral Coefficients)
- Handle background noise, reverberation, and different sampling rates
- Build and tune acoustic models that map audio features to phonemes
If this sounds unfamiliar, a solid course in Digital Signal Processing (DSP) is a good starting point before you dive into the ML side.
4. Natural Language Processing (NLP)
Once your system transcribes speech into text, it needs to understand what that text means. That’s where NLP comes in.
NLP is a core skill area for Speech Recognition Engineers, alongside acoustic modeling and data annotation.
Key NLP concepts you should know:
- Tokenisation and text normalisation
- Language models (n-gram and neural)
- Named Entity Recognition (NER)
- Intent detection and slot filling
Understanding NLP also helps you work on downstream applications like voice assistants and conversational AI, which are closely connected to speech recognition.
The speech recognition technology market is expected to reach $26 billion by 2028, growing at a CAGR of 17.2% from 2023. Investment in AI and machine learning is expected to rise by 30% over the next five years, directly driving demand for Speech Recognition Engineers.

5. ASR Frameworks and Tools
Knowing the theory is one thing. Knowing the tools the industry actually uses is another.
Here are the key frameworks you should get comfortable with:
- Kaldi: One of the most widely used open-source ASR toolkits, especially in research
- ESPnet: An end-to-end speech processing toolkit built on PyTorch
- Whisper (OpenAI): A powerful pre-trained ASR model, great for fine-tuning
- Wav2Vec 2.0 (Meta): A self-supervised speech representation model
- TensorFlow / PyTorch: For building custom models and pipelines
You don’t need to master all of them. But having hands-on experience with at least one ASR toolkit and one of the major deep learning frameworks is expected in most job roles.
6. Data Handling and Annotation
Speech models are only as good as the data they’re trained on. Continuous model training with diverse datasets is necessary to improve performance, especially across accents and noisy environments.
As a Speech Recognition Engineer, you’ll regularly work with:
- Large audio datasets (LibriSpeech, Common Voice, etc.)
- Data labelling and transcription pipelines
- Data augmentation techniques to improve model robustness
Understanding how to clean, annotate, and augment audio data is a skill that’s often underestimated but used constantly on the job.
Soft Skills That Actually Matter
Technical depth gets you the interview. These skills get you the job and help you grow.
Soft skills such as communication and teamwork are emphasized in 60% of job descriptions for Speech Recognition Engineers.
Collaboration: You’ll work with ML engineers, product managers, and linguists. Being able to explain your model’s behaviour clearly to non-technical stakeholders is genuinely valuable.
Problem-solving: Speech systems fail in unexpected ways. Debugging why a model misrecognises a particular accent or performs poorly in noisy conditions requires structured thinking.
Research mindset: This field moves fast. Engineers who stay curious and follow research papers (INTERSPEECH, ICASSP) tend to grow faster and build better systems.
Common Mistakes Beginners Make
1. Jumping to model training without understanding signal processing
Many beginners treat speech recognition like a standard text classification problem. Without understanding how audio is preprocessed, your model inputs will be poor and your results will be inconsistent. Learn DSP fundamentals first.
2. Ignoring linguistic diversity in datasets
Training only on standard accents and clean audio gives you a model that fails in real-world scenarios. Always test on diverse, noisy data from the beginning.
3. Overlooking evaluation metrics
Accuracy alone does not tell you how your ASR model is performing. Word Error Rate (WER) is the standard metric in this field. If you’re not tracking it, you’re not evaluating properly.
4. Skipping NLP basics
Some engineers focus entirely on the acoustic side and treat NLP as someone else’s problem. In practice, the two are deeply connected. Understanding language models makes you a much stronger Speech Recognition Engineer.
If you’re serious about learning effective AI prompts and want to apply them in real-world scenarios, don’t miss the chance to enroll in HCL GUVI’s Intel & IITM Pravartak Certified Artificial Intelligence & Machine Learning Course, co-designed by Intel. It covers Python, Machine Learning, Deep Learning, Generative AI, Agentic AI, and MLOps through live online classes, 20+ industry-grade projects, and 1:1 doubt sessions, with placement support from 1000+ hiring partners.
Conclusion
Speech recognition is one of the most technically demanding and rewarding areas in AI engineering. The skills you need range from signal processing and deep learning to NLP and data annotation, and the tools are evolving quickly. The good starting point is Python, then machine learning fundamentals, then audio-specific skills like acoustic modelling and ASR frameworks.
Build projects, contribute to open-source tools, and keep up with research. The field is growing fast, and engineers who can bridge the gap between raw audio and meaningful language understanding are going to be in high demand for years ahead.
FAQs
What is a Speech Recognition Engineer?
A Speech Recognition Engineer designs and builds systems that convert spoken language into text or commands. They work with machine learning models, acoustic modelling, and NLP to improve the accuracy and reliability of voice-driven applications.
What programming language is most important for speech recognition?
Python is the most widely used language in speech recognition due to its strong machine learning ecosystem. C++ is also important for building performance-sensitive, real-time applications.
Do I need a degree to become a Speech Recognition Engineer?
A degree in Computer Science or Electrical Engineering is commonly expected, but it is not strictly mandatory. A strong portfolio, open-source contributions, and relevant certifications can substitute effectively, especially for self-taught candidates.
What is acoustic modelling in speech recognition?
Acoustic modelling is the process of learning the relationship between audio features (like MFCCs) and phonemes. It is a core component of ASR systems and directly affects how accurately the system transcribes speech.
What frameworks should a Speech Recognition Engineer know?
The most commonly used frameworks are TensorFlow, PyTorch, Kaldi, Whisper, and Wav2Vec 2.0. Familiarity with at least one ASR toolkit alongside a deep learning framework is expected in most job roles.
What is Word Error Rate (WER) and why does it matter?
WER is the standard metric for evaluating ASR systems. It measures the number of word-level errors (substitutions, deletions, insertions) in the model’s output compared to the correct transcription. Lower WER means better accuracy.
How is NLP different from speech recognition?
Speech recognition converts audio into text. NLP processes and understands that text. In practice, both are closely connected — a voice assistant, for example, uses both a speech recognition system and an NLP layer to interpret and respond to what you said.
Can I enter this field from a software engineering background?
Yes. Many Speech Recognition Engineers transition from software engineering or data science roles. The key areas to build up machine learning, signal processing, and domain-specific tools like Kaldi or Whisper.are
Success Stories

About the Author
Lukesh S
A professional content writer who has experience in freelancing and now working as a Technical Content Writer at HCL GUVI having sound knowledge in Blog Writing and Creative Writing!
View all posts by Lukesh S
Connect with me @




















Did you enjoy this article?