


Artificial Intelligence and Machine Learning Articles
Text Classification with Scikit-learn: TF-IDF to BERT
MLflow Experiment Tracking: A Complete Beginner's Guide
Optuna for Hyperparameter Optimization
Explainable ML with SHAP Values: Interpreting Black-Box Models


Get In Touch For Details! Request More Information
LLM Engineer Skills: What You Need to Know in 2026
Jun 24, 2026 3 Min Read 24 Views
(Last Updated)
Table of contents
- TL;DR Summary:
- Who is an LLM Engineer, Really?
- Core LLM Engineer Skills You Need
- Programming and Software Engineering Basics
- Machine Learning and NLP Fundamentals
- LLM-Specific Skills
- Deployment and MLOps Skills
- Soft Skills That Are Easy to Overlook
- Common Mistakes Beginners Make
- How to Start Building These Skills
- Conclusion
- FAQs
- Is LLM engineering different from machine learning engineering?
- Do I need to train a model from scratch to become an LLM engineer?
- Is Python enough, or do I need other programming languages?
- How long does it take to become an LLM engineer starting from scratch?
- Can a fresher with no AI background become an LLM engineer?
- What's the difference between an LLM engineer and a prompt engineer?
TL;DR Summary:
An LLM engineer builds, fine-tunes, and deploys applications powered by large language models like GPT, Claude, and Gemini. The common LLM engineer skills required are solid Python skills, a working grasp of machine learning and transformer architecture, hands-on experience with prompt engineering, fine-tuning, and Retrieval-Augmented Generation (RAG), plus the ability to deploy models reliably using tools like Docker and cloud platforms. Most beginners start with ML foundations before moving into LLM-specific tools.
If you’ve been hearing the term “LLM engineer” everywhere and wondering what it actually takes to become one, you’re not alone. This role sits at the intersection of software engineering, machine learning, and natural language processing, and skill expectations can feel scattered across dozens of blog posts.
Here’s what you actually need to learn, in an order that makes sense if you’re starting from zero.
Who is an LLM Engineer, Really?
An LLM engineer designs, fine-tunes, and deploys applications built on large language models such as GPT, Claude, Llama, and Gemini. Rather than training a model from scratch, you typically start with an existing foundation model and adapt it to solve a specific business problem.
On a typical day, you’d be:
- Fine-tuning models for specific use cases
- Integrating LLM APIs into real applications
- Designing RAG pipelines so models can answer using your own company’s data
- Optimising cost, latency, and accuracy once the application is live
- Working closely with data scientists, product managers, and software engineers
Core LLM Engineer Skills You Need
These skills fall into five broad categories. You don’t need to master all of them on day one, but you should have working knowledge of each before applying for roles.
1. Programming and Software Engineering Basics
Python is non-negotiable here, since almost every LLM library, from Hugging Face Transformers to LangChain, is built around it. Beyond syntax, you’ll also need core software engineering habits: version control with Git, building clean APIs using frameworks like FastAPI, and the discipline to test and debug code systematically rather than by trial and error.
2. Machine Learning and NLP Fundamentals
Before you touch a large language model, you should understand how machine learning works in general. This includes supervised and unsupervised learning, how neural networks learn, and how gradient descent updates a model during training.
Specific to language models, focus on:
- Transformer architecture (self-attention, embeddings, positional encoding)
- Tokenisation: how raw text becomes numbers a model can actually process
- Basic linear algebra and probability, since both sit underneath every LLM concept
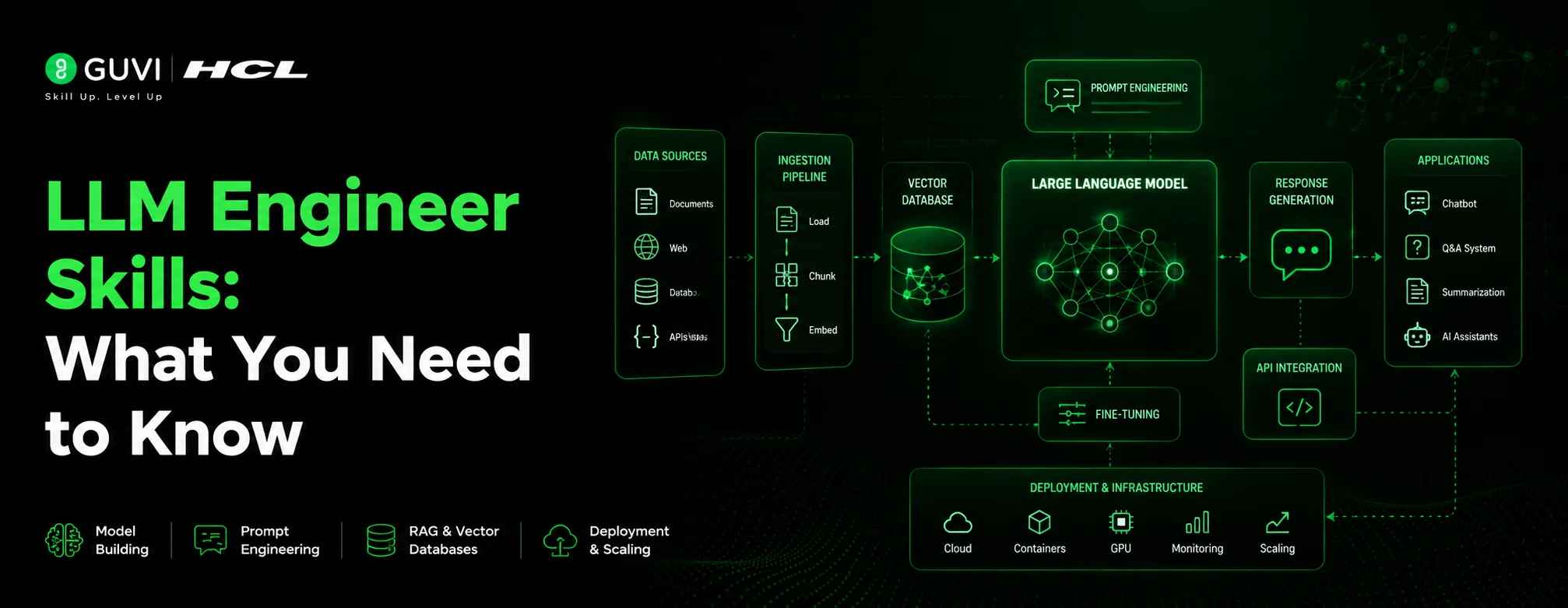
3. LLM-Specific Skills
This is where the role becomes distinct from a regular machine learning job.
- Prompt engineering: writing zero-shot, few-shot, and chain-of-thought prompts that produce consistent outputs
- Fine-tuning techniques like LoRA and PEFT, which adapt a model without retraining it from scratch
- RAG and vector databases: connecting an LLM to external knowledge using tools like Pinecone or Chroma
- Frameworks such as LangChain, LlamaIndex, and the Hugging Face ecosystem
- Working directly with LLM APIs from providers like OpenAI, Anthropic, and AWS Bedrock
4. Deployment and MLOps Skills
Knowing how a model works is only half the job. You also need to ship it into production reliably.
- Containerising applications with Docker and orchestrating them with Kubernetes
- Deploying on cloud platforms such as AWS, Azure, or GCP
- Monitoring latency, token usage, and cost once real users are hitting the application
- Setting up evaluation pipelines that catch hallucinations or quality drops early
5. Soft Skills That Are Easy to Overlook
LLM engineers rarely work in isolation. You’ll need to explain technical tradeoffs to non-technical stakeholders, collaborate across product and data teams, and stay mindful of safety and ethical considerations whenever a model interacts with real users.
The Transformer architecture powering almost every modern LLM, including GPT, Claude, and Gemini, was introduced in a single 2017 research paper. Today, most LLM engineering work focuses on adapting these existing models rather than building one from the ground up.

Common Mistakes Beginners Make
- Skipping ML fundamentals: Many beginners jump straight into LangChain tutorials without understanding how a transformer actually works. This makes debugging unpredictable model behaviour nearly impossible later on.
- Treating prompt engineering as the whole job: Writing good prompts matters, but it’s only one slice of the role. Employers also expect comfort with fine-tuning, RAG, and deployment.
- Ignoring cost and latency: A model that works fine in a notebook can turn slow and expensive in production. Start monitoring token usage and response time from your very first project.
How to Start Building These Skills
Begin with Python and core machine learning concepts before touching any LLM library. Once you’re comfortable with transformers and embeddings, build a small RAG project using an open-source model and a vector database, then move into fine-tuning and deployment.
If you’d rather follow a structured path than stitch tutorials together, programs that combine Python, ML foundations, and hands-on LLM projects, like the ones GUVI offers, can shorten this timeline considerably.
If you’re serious about learning effective AI prompts and want to apply them in real-world scenarios, don’t miss the chance to enroll in HCL GUVI’s Intel & IITM Pravartak Certified Artificial Intelligence & Machine Learning Course, co-designed by Intel. It covers Python, Machine Learning, Deep Learning, Generative AI, Agentic AI, and MLOps through live online classes, 20+ industry-grade projects, and 1:1 doubt sessions, with placement support from 1000+ hiring partners.
Conclusion
LLM engineering isn’t a single skill but a combination of solid programming, machine learning fundamentals, and hands-on experience with tools built specifically for large language models. You don’t need to learn everything at once.
Start with Python and ML basics, move into transformers and prompting, then build real projects using RAG and fine-tuning before worrying about deployment. As companies keep moving from AI experiments to production systems, engineers who can take a model from prototype to a reliable, cost-efficient application will stay in demand.
FAQs
1. Is LLM engineering different from machine learning engineering?
Yes. A machine learning engineer typically builds and trains models from scratch, while an LLM engineer adapts existing foundation models for specific applications using fine-tuning, prompting, and RAG.
2. Do I need to train a model from scratch to become an LLM engineer?
No. Most LLM engineering roles focus on adapting pre-trained models, since training one from the ground up requires resources only a handful of companies have.
3. Is Python enough, or do I need other programming languages?
Python covers most of the work, but knowing basic JavaScript or SQL helps when you’re integrating LLMs into full applications or working with structured data.
4. How long does it take to become an LLM engineer starting from scratch?
Beginners with no coding background usually need six to twelve months of consistent learning, while those with an existing ML or software background can transition in two to four months.
5. Can a fresher with no AI background become an LLM engineer?
Yes, but you’ll need to build ML fundamentals first. Start with Python and statistics, then move into transformers and LLM-specific tools through hands-on projects.
6. What’s the difference between an LLM engineer and a prompt engineer?
A prompt engineer focuses mainly on designing effective prompts, while an LLM engineer handles the full pipeline, including fine-tuning, RAG, deployment, and cost optimisation.
Success Stories

About the Author
Lukesh S
A professional content writer who has experience in freelancing and now working as a Technical Content Writer at HCL GUVI having sound knowledge in Blog Writing and Creative Writing!
View all posts by Lukesh S
Connect with me @





















Did you enjoy this article?