


Artificial Intelligence and Machine Learning Articles
Skills for Multimodal AI Development: What You Need to Know
BentoML Tutorial: From Model to Production API
Deploying a Machine Learning Model as a FastAPI Microservice


Get In Touch For Details! Request More Information
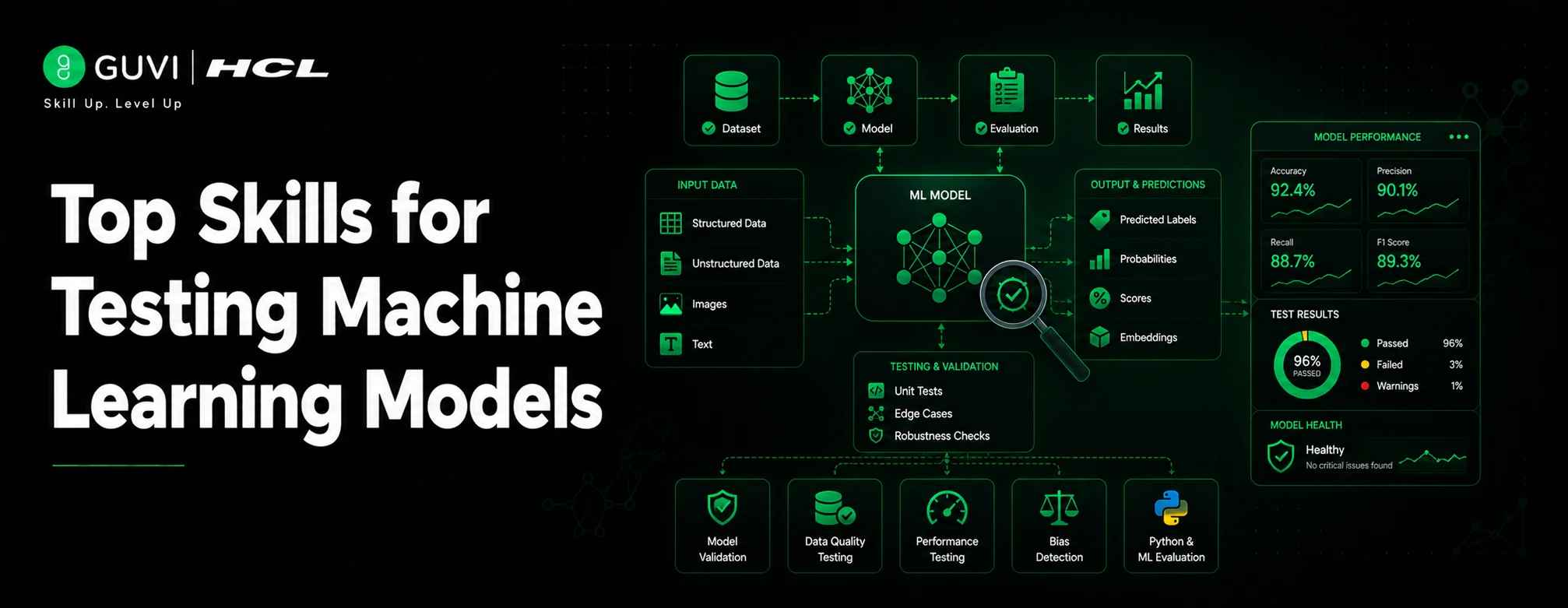
Top Skills for Testing Machine Learning Models in 2026 (Beginner’s Guide)
Jul 03, 2026 5 Min Read 27 Views
(Last Updated)
Machine learning models don’t fail the way regular software does. There’s no error message, no crash, no red flag waving at you. A model can run perfectly fine and still be quietly wrong, missing fraud cases, rejecting the wrong loan applicants, or showing the same product to every single user. That’s exactly why ML testing has become its own specialty, separate from regular QA.
If you’re trying to break into this field or sharpen your existing skills, this guide walks through everything that actually matters, from the data side to the production side, without the jargon overload.
TL;DR
- Good ML testing starts before the model even sees data quality, drift, and bias checks come first
- Accuracy alone is a misleading metric; precision, recall, and validation strategy matter more
- Specialized methods like adversarial and metamorphic testing catch what standard tests miss
- Explainability tools like SHAP and LIME help teams understand why a model failed
- MLOps skills (CI/CD, pipeline testing) are now considered core, not optional
- Career paths range from ML Test Engineer to AI Risk and Compliance Analyst
Table of contents
- What Does Testing Machine Learning Models Mean?
- Top Skills for Testing Machine Learning Models
- Data Validation and Preprocessing
- Mathematical and Statistical Understanding
- Model Evaluation Metrics
- Specialized ML Testing Methods
- Explainability and Error Analysis
- Software Engineering and MLOps Skills
- Production Monitoring and Model Observability
- Career Opportunities After Learning ML Testing Skills
- Conclusion
- FAQs
- Do I need to know machine learning to become an ML test engineer?
- What programming language should I learn first for ML testing?
- Is ML testing different from regular software QA?
- Which skill should a beginner focus on first?
- Can I move from regular QA into ML testing?
What Does Testing Machine Learning Models Mean?
Testing an ML model isn’t about whether the code runs, it’s about whether the model’s decisions hold up. Are they accurate? Fair? Will they still make sense once real-world data drifts from the training data?
That’s the difference from regular software testing. Code either passes or fails. ML models can pass every test and still misbehave once they meet messy, real-world inputs. So testing has to go deeper, into the data, the edge cases, the slow performance decay, and the bias nobody’s watching for.
MIT research found that some widely used facial analysis systems had error rates under 1% for light-skinned men but over 30% for dark-skinned women. This gap only surfaced because someone tested the model across demographic slices instead of trusting the accuracy score.
Top Skills for Testing Machine Learning Models
1. Data Validation and Preprocessing
Every good ML model testing process starts with data. Even a powerful model can fail if the data is incomplete, biased, duplicated, or wrongly labelled.
- Data Quality Auditing: This skill helps check missing values, duplicate records, wrong formats, schema mismatches, and data leakage. A loan approval model, for example, should never use “final approval status” as an input because that gives the model the answer in advance.
- Statistical Profiling: This helps understand how the data behaves before the model learns from it. A fraud detection model may show high accuracy because most transactions are genuine. The real test is whether it can still detect the rare fraud cases correctly.
- Drift Detection: Real-world data changes after deployment. A demand forecasting model trained on regular weekday orders may fail during festivals, rain, holidays, or sudden market changes. Drift detection helps catch this shift early.
- Tool Proficiency: Tools like Pandas, Great Expectations, TensorFlow Data Validation, and Evidently AI make data checks faster and repeatable. They help teams catch data issues before they damage model performance.
2. Mathematical and Statistical Understanding
ML testing becomes much stronger when there is a basic understanding of statistics and model logic. The goal is not to become a data scientist. The goal is to understand why a model behaves the way it does.
- Hypothesis Testing: This helps compare two model versions fairly. A new recommendation model may show a small improvement, but hypothesis testing helps confirm whether that improvement is real or just random variation.
- Probability Distributions: Many ML models give confidence scores instead of fixed answers. A medical image model with 55% confidence needs a very different review from a model with 96% confidence.
- Linear Algebra Basics: ML systems often work with vectors, matrices, embeddings, and tensors. A search model, for example, converts words into embeddings before comparing how similar two queries are.
- Algorithmic Logic: Regression, classification, clustering, decision trees, and neural networks all behave differently. Understanding their logic helps create better test cases for each model type.
Tesla’s self-driving systems are tested against millions of simulated miles before a single real mile, because catching a rare edge case in simulation is a lot cheaper than catching it on the road.

3. Model Evaluation Metrics
Accuracy alone can be misleading. A model can look accurate on paper and still fail in the areas that matter most.
- Classification Metrics: Accuracy, precision, recall, F1-score, ROC-AUC, PR-AUC, and confusion matrix help evaluate classification models. In cancer detection, recall is critical because missing a positive case can be more dangerous than raising a false alert.
- Regression Metrics: MAE, MSE, RMSE, R² score, and residual analysis help test models that predict numbers. In house price prediction, RMSE shows how far the predicted price is from the actual price.
- Validation Strategies: Train-test split, stratified sampling, holdout validation, and K-Fold cross-validation help check whether the model is stable. Stratified sampling is useful when rare classes like fraud, defects, or disease cases are present.
- Overfitting and Underfitting Detection: A model that performs very well on training data but poorly on validation data may be memorizing instead of learning. A 98% training accuracy and 72% validation accuracy is a clear warning sign.
Advance your testing career with HCL GUVI’s Advanced Selenium with Java Course and build expertise in modern automation testing practices. Learn advanced Selenium concepts, test automation frameworks, Java programming, and real-world testing workflows through hands-on projects designed for aspiring QA and automation professionals.
4. Specialized ML Testing Methods
Machine learning models need deeper testing because small input changes can sometimes create unexpected results. These methods help check whether the model behaves logically.
- Behavioral Testing: This checks whether the model responds sensibly to input changes. A hiring model, for example, should not change a candidate’s suitability score just because the name on the resume changes.
- Metamorphic Testing: This is useful when the exact expected output is hard to define. A shoe image rotated slightly should still be classified as a shoe, not as a bag.
- Adversarial Testing: This involves testing the model with noisy, corrupted, or manipulated inputs. A spam detection model should still identify spam even when extra symbols, spaces, or spelling changes are added.
- Bias and Fairness Auditing: This checks whether predictions are fair across user groups, regions, languages, or demographic segments. A credit scoring model should not reject applicants from one location when income and repayment history are similar.
5. Explainability and Error Analysis
A strong ML testing process does not stop at saying the model failed. It also explains where the model failed and why that failure matters.
- Feature Importance Analysis: SHAP, LIME, and permutation importance help show which features influenced a prediction. A loan model depending too much on pin code may raise fairness concerns.
- Error Slicing: Errors can be grouped by language, location, device, customer type, product category, or input pattern. A speech recognition model may perform well in standard English but fail with regional accents.
- False Positive and False Negative Review: Wrong predictions carry different risks. A false positive in fraud detection may block a genuine customer. A false negative may allow fraud to pass.
- Model Interpretability: Some models need clear explanations for business teams, compliance teams, or users. This is especially important in finance, healthcare, hiring, and insurance.
6. Software Engineering and MLOps Skills
ML models do not work alone. They run inside pipelines, APIs, applications, dashboards, and deployment systems. Testing also needs to cover this full environment.
- Core Programming: Python, R, and SQL help create reusable test scripts and validate large datasets. Python can check thousands of model outputs automatically instead of reviewing them one by one.
- Pipeline Integration Testing: The complete journey from data ingestion to feature engineering, model inference, and final output needs validation. A model may be accurate, but the system can still fail if one feature column goes missing during deployment.
- CI/CD and Automation: PyTest, GitHub Actions, Jenkins, and GitLab CI help run checks during every deployment. This reduces the chance of releasing a model with broken data checks or weak performance.
- Artifact Tracking: MLflow, DVC, and Weights & Biases help track datasets, model versions, hyperparameters, and results. This makes it easier to find what changed when model performance drops.
7. Production Monitoring and Model Observability
A model can perform well during testing and still fail in production. Real users, changing data, and new business conditions can affect its performance.
- Prediction Monitoring: Live prediction patterns, confidence scores, and unusual outputs need regular tracking. A recommendation model suddenly showing the same product to every user may indicate a production issue.
- Performance Decay Tracking: Model performance can reduce over time as real-world data changes. A sales forecasting model trained on last year’s buying behavior may become less accurate during a new market trend.
- Shadow Testing: A new model can run silently beside the existing model before full release. A new fraud detection model, for example, can be observed in the background while the older model continues making real decisions.
- Rollback Readiness: Production teams need a safe way to return to an earlier model version. A pricing model that starts giving unstable outputs after deployment should be rolled back before it affects revenue.
Career Opportunities After Learning ML Testing Skills
Strong ML testing skills open doors across a growing set of roles, since every company deploying machine learning needs people who can validate and monitor these systems before and after release.
- ML Test Engineer: Focuses on validating datasets, checking model logic, and building automated test suites for model pipelines. This role suits someone who enjoys writing scripts that catch issues before deployment rather than after.
- ML Quality Assurance (QA) Specialist: Works closely with data science teams to test model outputs against business requirements, often handling classification and regression metrics, validation strategies, and error analysis on a daily basis.
- MLOps Engineer: Owns the pipeline that takes a model from training to production, including CI/CD automation, artifact tracking, and rollback readiness. This role blends software engineering with ML testing know-how.
- AI/ML Risk and Compliance Analyst: Common in finance, healthcare, and insurance, this role centers on bias and fairness auditing, model interpretability, and ensuring predictions hold up to regulatory scrutiny.
- Data Validation Engineer: Specializes in data quality auditing, statistical profiling, and drift detection, often working upstream of the model itself to make sure the inputs are trustworthy.
- Model Monitoring/Observability Engineer: Tracks live prediction patterns, performance decay, and shadow testing results once a model is in production, acting as an early warning system for silent failures.
- AI Test Automation Lead: A senior path for engineers who build and manage testing frameworks across multiple models and teams, often combining Python/SQL scripting with CI/CD tooling like Jenkins or GitHub Actions.
Conclusion
ML testing isn’t a one-time checklist, it’s an ongoing relationship with a model that keeps changing once it meets real users and real data. A model can pass every metric check and still fail in production if nobody’s watching for drift or bias.
You don’t need to master all seven areas at once. Most people start with data validation and basic metrics, then build the rest on the job. What matters most isn’t knowing every tool, it’s the instinct to ask “what happens when this meets the real world?” That question separates good ML testing from a checklist that just looks thorough.
FAQs
Do I need to know machine learning to become an ML test engineer?
You need a working understanding of how models are trained and evaluated, but you don’t need to build models from scratch. Knowing how to read metrics and spot data issues matters more than deep algorithm expertise.
What programming language should I learn first for ML testing?
Python is the most widely used, since most ML tooling (Pandas, SHAP, MLflow, PyTest) is Python-based. SQL is a close second for querying and validating large datasets.
Is ML testing different from regular software QA?
Yes. Regular QA checks if code behaves as expected. ML testing checks if a model’s predictions are statistically sound and stable, which requires data and metrics knowledge that traditional QA doesn’t cover.
Which skill should a beginner focus on first?
Data validation. Almost every downstream issue, from bias to poor accuracy, traces back to a data problem, so this is the highest-leverage skill to learn early.
Can I move from regular QA into ML testing?
Yes, this is a common path. QA professionals already understand testing principles; adding statistics, evaluation metrics, and a few ML-specific tools is usually enough to transition.
Success Stories

About the Author
Vaishali
I'm a seasoned writer with four years of experience across technical, non-technical, and just about every genre or niche you can imagine. Adaptable and curious, I enjoy exploring new topics and making information engaging and easy to understand. Fueled by a steady stream of tea, I approach each project with creativity, reliability, and genuine enthusiasm for storytelling.
View all posts by Vaishali
Connect with me @




















Did you enjoy this article?