


Artificial Intelligence and Machine Learning Articles
Experiment: Figma to Replit Plugin
Skills Required to Become a Speech Recognition Engineer in 2026
Computer Vision Engineer Skills Roadmap: A Step-by-Step Guide
What is Replit’s New Database Editor? A Beginner-Friendly Guide


Get In Touch For Details! Request More Information

Vanishing Gradient Problem in Deep Learning
Jun 05, 2026 5 Min Read 604 Views
(Last Updated)
Face recognition, translation, image generation, and AI chatbots are impressive today, but training deep neural networks was not always stable. As networks became deeper, optimization issues created training instability.
One major reason was the vanishing gradient problem. During training, gradients became extremely small, weakening weight updates and slowing learning, especially in early layers.
Modern AI breakthroughs became possible not only because models became deeper, but because researchers learned how to stabilize gradient flow. This article explains why the vanishing gradient problem still matters in modern deep learning.
Table of contents
- TL;DR
- How the Vanishing Gradient Problem Happens
- Why Deep Neural Networks Struggle to Learn
- How Backpropagation Causes Gradient Shrinkage
- Why Sigmoid and Tanh Are a Problem for Training
- Vanishing vs Exploding Gradients
- Real-World Impact on Deep Learning
- How ReLU Changed Deep Learning
- Why LSTM Was a Major Breakthrough
- ResNet: Solving Gradient Flow Challenges in Deep Networks
- Practical Example: Comparing Sigmoid and ReLU Gradient Behaviour
- Modern Techniques Used to Stabilize Gradients
- Xavier Initialization
- He Initialization
- Batch Normalization
- Layer Normalization
- Gradient Clipping
- The Ongoing Challenge of Vanishing Gradients
- Conclusion
- FAQs
- What is the vanishing gradient problem in deep learning?
- Why do gradients vanish in neural networks?
- Which activation functions commonly cause vanishing gradients?
- How does ReLU help solve the vanishing gradient problem?
- What is the difference between vanishing and exploding gradients?
- Is the vanishing gradient problem completely solved today?
TL;DR
- The vanishing gradient problem occurs when gradients become extremely small in deep neural networks during backpropagation.
- This limits weight updates in early layers and slows down or stops the learning process.
- Sigmoid and tanh activation functions contribute to this problem because their derivatives progressively reduce through repeated multiplication.
- Modern solutions such as ReLU (Rectified Linear Unit), LSTM (Long Short-Term Memory), residual networks, and batch normalization help stabilize gradient flow.
What is the Vanishing Gradient Problem?
The vanishing gradient problem occurs when gradient values become extremely small as they backpropagate through a deep neural network. As a result, earlier layers receive only minimal updates, which slows down or even stops learning. This issue primarily affects very deep neural networks and sequence-based architectures.
How the Vanishing Gradient Problem Happens

Deep neural networks learn through a process called backpropagation. During this process, errors are calculated, and gradients are sent back through the layers to update weights.
The problem arises when traveling backward through a deep neural network; the gradients begin to progressively shrink. This sends extremely weak learning signals back to the earliest layers, making these layers extremely difficult to train.
In essence, the neural network is “forgetting how to learn” in its earlier layers. The mathematical origin of this problem stems from a process of multiplication:
Gradient ≈ d₁ × d₂ × d₃ × … × dₙ
As more and more numbers less than 1 are multiplied, the result quickly becomes extremely small, and updates to earlier layers become too small to make any impact.
To understand how information flows across layers in deep learning systems, understanding neural networks and their components becomes important.
Why Deep Neural Networks Struggle to Learn

In shallow networks, there are not that many layers. Thus, the gradients have only a few math operations to pass through during backpropagation. However, deep neural networks have dozens and often hundreds of layers.
The deeper a neural network goes, the more math operations the gradients go through during backpropagation, with each small derivative multiplying and weakening the gradient. After this has occurred numerous times, it is significantly reduced.
This creates several training challenges:
- Earlier layers fail to learn effectively.
- The feature extraction capabilities of the network are weakened.
- The network learns at a significantly reduced pace.
- The overall training process is inefficient and unstable.
The challenges in deep neural networks become more visible as architectures grow deeper and optimization becomes harder.

How Backpropagation Causes Gradient Shrinkage
Backpropagation functions by determining how much each weight contributed to the final error and then making adjustments to each weight in order to reduce the error for the next time.
The challenge in this problem is that these gradients must reach all the way from the output layer back to the input layers.
During their journey backward, the gradients are multiplied over and over with the derivatives of the activation functions. If these activation function derivatives are continually small, then the learning signal will become weak in every subsequent layer.
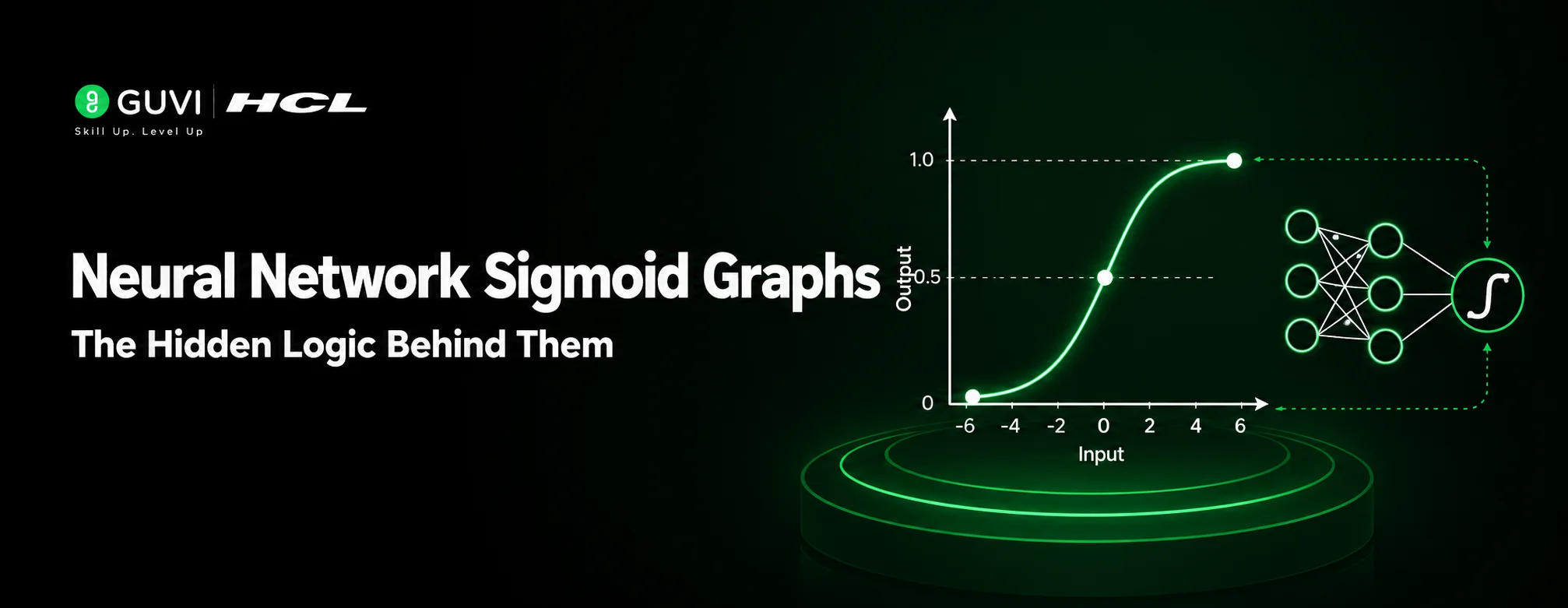
Why Sigmoid and Tanh Are a Problem for Training

Activation functions give neural networks non-linear properties, without which deep neural networks would behave like a linear regression model. Some of these functions have the disadvantage of not allowing gradients to pass through the layers effectively. Sigmoid is one of the most famous examples:
σ(x) = 1 / (1 + e⁻ˣ)
The sigmoid activation function pushes its output values toward a range between 0 and 1. While useful in prediction problems, in the saturating region, where the output value is approaching 1 or 0, the gradient is very small.
Repeated multiplication results in rapidly diminishing gradients that may lead to dying neurons and, as a result, a slowed or halted learning process. It’s a misconception that sigmoid is “bad” itself. Rather, the issue arises when its outputs saturate.
The tanh function exhibits the same problem, but since its outputs are centered around 0, the effect is not as pronounced. The gradient flow of any neural network depends on its activation function.
The behavior of activation functions in artificial neural networks directly affects how gradients propagate during training.
Vanishing vs Exploding Gradients
While vanishing gradients slow down learning, the opposing problem of exploding gradients destabilizes learning. Exploding gradients send excessively large signals through neural networks, which cause instabilities and incorrect weight updates.
Essentially:
Vanishing gradients = Slow or stopped learning.
Exploding gradients = Unstable learning.
Both arise due to repeated multiplication during backpropagation. Networks trained with exploding gradients often display unstable results and may cease to converge entirely. Gradient clipping is a method commonly employed to prevent exploding gradients. They have a significant impact on how the gradient descent algorithm updates the weights of neural networks.
Real-World Impact on Deep Learning

The vanishing gradient problem affects far more than learning speed. It is directly linked to how accurately a deep learning model understands features.
For image recognition, early layers learning simple edges and textures could not learn if the gradient signal was weak. For natural language processing, where long-term dependencies need to be learned, this problem became even more critical, as preserving information over a longer sequence became significantly harder because of vanishing gradients.
This resulted in:
- Slow learning speed.
- Weak feature detection.
- Difficulty learning long-term dependencies.
- Low model accuracy.
- High model instability.
These problems have historically limited the capabilities of modern image and speech recognition systems, as well as natural language models, before developments in neural network architecture became effective.
Before Residual Networks (ResNets), training extremely deep neural networks was considered nearly impossible because of optimization instabilities and vanishing gradient problems.
Residual connections introduced shortcut paths that allow gradients to flow more effectively through the network during training.
This breakthrough made it practical to train hundreds of layers, dramatically improving deep learning performance in areas like computer vision and paving the way for many modern AI architectures.
How ReLU Changed Deep Learning

The introduction of the Rectified Linear Unit, or ReLU, significantly improved deep learning training. Unlike sigmoid and tanh, ReLU does not saturate in its positive region, meaning that it allows gradients to propagate through its layers more effectively.
Instead of compressing the value, gradients remain stable during propagation. This resulted in:
- Faster convergence.
- More stable training.
- Scalability to greater depths.
- Stronger gradient propagation.
Modern networks almost universally use the ReLU activation function and derivatives such as Leaky ReLU and ELU, which further improve upon its weaknesses.
If you want to understand how modern deep learning systems improve optimization and training stability, this eBook provides a practical introduction to neural network architectures and gradient flow concepts.
Why LSTM Was a Major Breakthrough
Long-term dependencies were a major problem for recurrent neural networks because gradients tend to diminish over sequence steps. This was an obstacle in sequence learning, such as machine translation, speech recognition, and time series prediction.
LSTM networks were the solution that solved this problem. They do not simply pass information directly through recurrent connections; LSTMs utilize memory cells and gate layers to better manage the information that gets sent forward.
The important aspect was that LSTM preserved long-term gradient flow, and this allowed networks to retain information for longer periods.
ResNet: Solving Gradient Flow Challenges in Deep Networks
One of the breakthroughs in modern deep learning was residual connections. Instead of passing gradients through every layer sequentially, ResNet introduced shortcut paths called skip connections.
The gradients no longer shrank repeatedly through successive layers. Earlier, training very deep networks was unstable, and accuracy dropped as layers increased. Residual connections stabilized gradient flow and enabled much deeper neural networks to train effectively.
The core concept in ResNet is identity mapping, where layers learn residual mappings instead of entirely new transformations. This allowed networks to scale beyond previous depth limitations.
Practical Example: Comparing Sigmoid and ReLU Gradient Behaviour
Let’s consider a small experiment we will run using TensorFlow to compare Sigmoid and ReLU. Two small neural networks are constructed below using different activation functions. One uses Sigmoid, and the other uses ReLU.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
def build_model(activation):
model = Sequential([
Dense(64, activation=activation, input_shape=(100,)),
Dense(64, activation=activation),
Dense(64, activation=activation),
Dense(1, activation=’sigmoid’)
])
model.compile(
optimizer=’adam’,
loss=’binary_crossentropy’,
metrics=[‘accuracy’]
)
return model
sigmoid_model = build_model(‘sigmoid’)
relu_model = build_model(‘relu’)
print(“Models created successfully.”
Building a neural network using TensorFlow can help you understand how activation functions affect gradient flow practically.
Modern Techniques Used to Stabilize Gradients
There are various other techniques that modern neural networks rely on. Some of them are:
1. Xavier Initialization
Helps preserve activation variance evenly through the layers, which means that the signal remains stable.
2. He Initialization
Similar to Xavier, it is specifically useful for ReLU networks and preserves a stronger signal through the layers.
3. Batch Normalization
Normalizes input to layers and accelerates training speed. This also aids in improving optimization stability.
The core idea of batch normalization is to regulate activation distributions during training.
4. Layer Normalization
Mainly useful for recurrent neural networks and transformers, where maintaining gradient stability is crucial.
5. Gradient Clipping
Used to prevent very large gradients during backpropagation to make sure training remains stable.
The Ongoing Challenge of Vanishing Gradients
Although the vanishing gradient problem is more manageable, there are some situations where gradient issues persist and continue to challenge researchers. Those include extremely deep networks, long-sequence models, RNNs, badly initialized networks, or highly constrained models.
Today, modern research is no longer centered around whether gradients vanish, but rather on how to enable them to propagate stably in deeper and more complex architectures without losing learning signals.
To learn more about training neural networks and gradient descent optimization, explore HCL GUVI’s Artificial Intelligence & Machine Learning Course, which helps learners understand activation functions, optimization techniques, and deep learning architectures in detail.
Conclusion
The vanishing gradient problem was one of the biggest obstacles in early deep learning. As neural networks became deeper, unstable gradient flow made training increasingly difficult.
Researchers eventually solved many of these challenges through better activation functions, residual networks, improved initialization methods, and normalization techniques. These breakthroughs made modern deep learning significantly more stable and scalable.
Today’s AI systems succeeded not only because models became deeper, but because researchers learned how to stabilize learning itself.
FAQs
1. What is the vanishing gradient problem in deep learning?
The vanishing gradient problem occurs when gradients become extremely small during backpropagation. This weakens weight updates in earlier layers and slows or stops learning in deep neural networks.
2. Why do gradients vanish in neural networks?
Gradients vanish because backpropagation repeatedly multiplies derivatives smaller than 1. Over many layers, this multiplication causes gradients to shrink exponentially.
3. Which activation functions commonly cause vanishing gradients?
Sigmoid and tanh activation functions commonly contribute because their derivatives become very small in saturated regions.
4. How does ReLU help solve the vanishing gradient problem?
ReLU avoids saturation in positive regions, allowing stronger gradients to flow backward during training. This improves optimization stability and convergence speed.
5. What is the difference between vanishing and exploding gradients?
Vanishing gradients become too small and weaken learning, while exploding gradients become excessively large and destabilize training through massive weight updates.
6. Is the vanishing gradient problem completely solved today?
No. Modern architectures significantly reduced the issue, but gradient stability remains important in very deep networks, recurrent systems, and long-sequence AI models.
Success Stories

About the Author
Vishalini Devarajan
An Aerospace Engineer turned content writer, I focus on making complex concepts easy to understand through well-structured, reader-friendly blogs. Whether it’s a technical topic or a non-technical one, I love creating content that is clear, engaging, and impactful.
View all posts by Vishalini Devarajan
Connect with me @




















Did you enjoy this article?