


Artificial Intelligence and Machine Learning Articles
Experiment: Figma to Replit Plugin
Skills Required to Become a Speech Recognition Engineer in 2026
Computer Vision Engineer Skills Roadmap: A Step-by-Step Guide
What is Replit’s New Database Editor? A Beginner-Friendly Guide


Get In Touch For Details! Request More Information

Sigmoid Function in Binary Classification & Neural Networks
May 12, 2026 4 Min Read 356 Views
(Last Updated)
Table of contents
- Introduction to Sigmoid Function
- TL;DR
- Interpreting the S-Shaped Curve
- Mathematical Formulation and Learning Behavior
- The Case for Sigmoid in Binary Classification
- Sigmoid as an Activation Function in Neural Networks
- The Role of Sigmoid in Gradient Descent Optimization
- The Weaknesses of the Sigmoid Function
- The Modern Deep Learning Perspective on Sigmoid
- A Comparison between Sigmoid and Other Activation Functions
- Applications of the Sigmoid Function in the Real World
- Practical Example with Code
- Key Intuition Behind Sigmoid
- Conclusion
- FAQs
- What is the sigmoid function used for?
- Why is the sigmoid called a logistic function?
- Why is the sigmoid not used in deep hidden layers?
- What is the role of the sigmoid in neural networks?
- Is sigmoid still used in modern deep learning?
- Can sigmoid be used for multi-class classification?
Introduction to Sigmoid Function
Sigmoid is one of the most important fundamental concepts in machine learning and artificial intelligence.
At first glance, sigmoid appears extremely simple; however, it plays a major role in how models process data and arrive at conclusions.
Fundamentally, the sigmoid function is used to transform a raw numerical value into a probability value. Therefore, it is perfectly suited for any problems that require a yes or no classification of outcomes.
The function does not just convert a number into probability; it turns uncertainty into measurable probability on which decisions can be made.
In this blog post, we will look at how the sigmoid function is applied in binary classification and neural networks, its importance, problems, and applications.
TL;DR
- The sigmoid function is an extremely useful function in machine learning to transform a real value into a probability.
- Sigmoid is utilized for the output layer of neural networks and binary classification problems such as logistic regression.
- As an activation function, the sigmoid is a nonlinear function and introduces non-linearity for neural networks, which allows the network to learn any complex patterns.
- Sigmoid suffers from the vanishing gradient problem, and that may prevent Sigmoid from being used for deep hidden layers.
- Despite the appearance of new alternatives in deep learning, the sigmoid is still necessary in providing probability outputs for AI systems.
What is the Sigmoid Function?
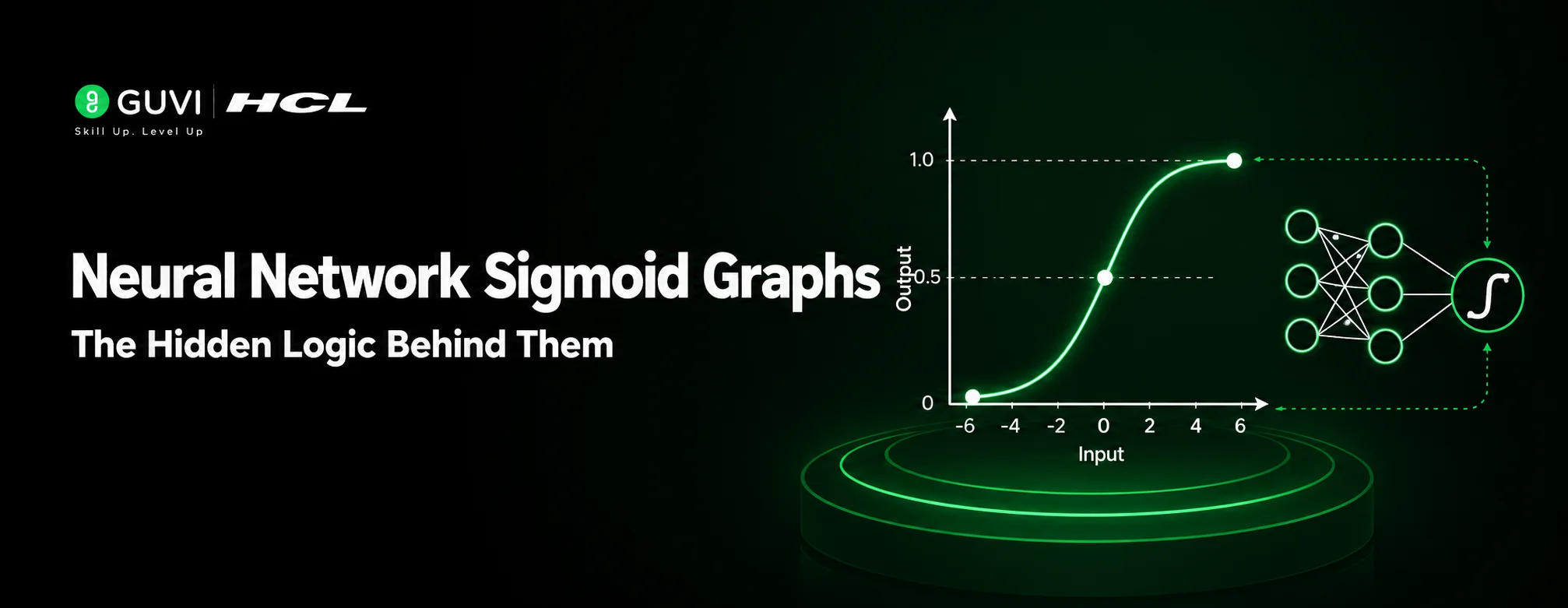
The sigmoid function is a mathematical function that maps any real-valued input into a value between 0 and 1. It is also known as the logistic function and is characterized by its smooth S-shaped curve. It is commonly used in machine learning models to produce probability-based outputs.
Interpreting the S-Shaped Curve
The sigmoid function’s defining characteristic is its S-shape. This shape is not just visually smooth, but holds significant implications for decision-making.
The shape ensures that outputs are clipped between 0 and 1 when input values are very high or low, meaning there is never a sudden jump in confidence.
This smoothness also ensures that models do not make unstable predictions, which is why the sigmoid is so heavily associated with decision boundaries in binary classification problems.
Mathematical Formulation and Learning Behavior
The mathematical definition of the sigmoid function is:
(x) = 1 / (1 + e^-x)
The derivative of the sigmoid function is:
(x) = (x)(1 – (x))
This derivative plays a key role in how a neural network’s weights are optimized during backpropagation via gradient descent.
The Case for Sigmoid in Binary Classification
In binary classification, models need to predict the probability of one of two classes. The sigmoid function is ideal because it converts raw model scores into values between 0 and 1, making the output easy to interpret as a probability.
Outputs above 0.5 are typically classified as one class, while values below 0.5 represent the other. This makes sigmoid useful for tasks like spam detection and fraud detection.
Sigmoid is also heavily used in logistic regression models for probability-based classification tasks. Learn more in this guide on logistic regression in machine learning.
As sigmoid outputs values between 0 and 1, it keeps the data properly scaled. Neural networks use activation functions to learn complex patterns from data. This guide on neural networks in machine learning explains how these layers and activations work together.
Sigmoid as an Activation Function in Neural Networks
In neural networks, activation functions are what determine how much a signal should be amplified or attenuated based on its input. Without nonlinearities in the activation functions, neural networks could not be used to model complex interactions and would effectively function as basic linear models.
The Role of Sigmoid in Gradient Descent Optimization
In a model, learning happens through adjusting weights so that the error the model produces when a prediction is made is reduced. Gradient descent helps optimize this process by finding the direction of steepest descent with respect to the loss function, usually binary cross-entropy.
The derivative of the sigmoid is needed to compute the gradients, which are used to update the weights in the model; however, if the value of x is very large or very small, the slope becomes very shallow, close to zero. This leads to learning in deeper layers becoming very slow.

The Weaknesses of the Sigmoid Function
There is a major drawback with the sigmoid function. When x values approach 0 or 1, the function gets “saturated”, meaning that the gradients become very close to zero.
This can cause problems for deep neural networks and make it very difficult to update the weights in earlier layers due to vanishing gradients.
The Modern Deep Learning Perspective on Sigmoid
Modern deep learning networks will no longer make use of the sigmoid activation function across the entire network. However, sigmoid still remains fundamental as the activation function on the output layer of any classification system and is still of great interest.
In place of sigmoid, activation functions such as ReLU (Rectified Linear Unit) and GELU (Gaussian Error Linear Unit) are used, which suffer from fewer vanishing gradient issues and improve the overall training time of models.
Modern architectures often replace sigmoid with functions like ReLU to improve training efficiency. You can understand this better through neural networks and their components.
A Comparison between Sigmoid and Other Activation Functions
Different activation functions work better depending on the architecture of the network and the particular task of the model. Sigmoid, for example, is best used as the output layer for classification problems as it provides a probability-based interpretation of data.
ReLU functions provide the advantage that they are faster than the sigmoid activation function and do not cause the same issues with gradient optimization. TanH provides a similar shape to sigmoid, but a range of outputs between -1 and 1.
Applications of the Sigmoid Function in the Real World
The sigmoid function finds wide use in many AI and real-world systems. In addition to the previously mentioned classification problems, sigmoid also makes use of the following systems:
- Spam detection systems
- Fraud detection systems
- Medical diagnosis models
- Sentiment analysis models
- Used as an activation function in classification problems to keep the output within an interpretable range
Many modern artificial intelligence systems use neural networks to make probability-based decisions. This introduction to artificial neural networks explains their real-world significance.
Practical Example with Code
Below is a simple Python example demonstrating how the sigmoid function converts inputs into probability outputs.
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
data = np.array([-5, -2, 0, 2, 5])
predictions = sigmoid(data)
for i, val in enumerate(predictions):
print(f”Input: {data[i]}, Probability: {val}”)
To deepen your understanding, refer to this ebook, which explains activation functions, neural networks, and practical implementations clearly.
The sigmoid function was originally used in biology to model population growth.
Today, the same mathematical curve powers AI decision-making systems used for fraud detection, disease diagnosis, and filtering billions of emails every day.
Key Intuition Behind Sigmoid
This is where the strength of the sigmoid comes into play. It reduces any complexity into a probability between 0 and 1, whilst maintaining the relative distances of values.
With this, models are not prone to flip-flopping between classes.
Its S-shape gives rise to smoothly defined class boundaries that are predictable and easy to understand.
To gain hands-on expertise in machine learning, neural networks, and deep learning, explore HCL GUVI’s AI & Machine Learning course. It focuses on real-world projects and practical understanding of concepts like activation functions and gradient descent.
Conclusion
The sigmoid function remains a core concept in machine learning, especially in binary classification and probability-based decision systems.
While it is no longer dominant in deep hidden layers, its importance in output layers is undeniable. Understanding sigmoid helps you understand how machines turn raw data into meaningful decisions.
FAQs
1. What is the sigmoid function used for?
It is used to convert numerical values into probabilities in binary classification problems.
2. Why is the sigmoid called a logistic function?
It comes from logistic growth models and produces an S-shaped curve used for probability mapping.
3. Why is the sigmoid not used in deep hidden layers?
Because it suffers from the vanishing gradient problem, which slows down learning.
4. What is the role of the sigmoid in neural networks?
It acts as an activation function that converts outputs into probabilities.
5. Is sigmoid still used in modern deep learning?
Yes, it is widely used in output layers for binary classification tasks.
6. Can sigmoid be used for multi-class classification?
No, sigmoid is mainly used for binary classification, while softmax is used for multi-class problems.
Success Stories

About the Author
Vishalini Devarajan
An Aerospace Engineer turned content writer, I focus on making complex concepts easy to understand through well-structured, reader-friendly blogs. Whether it’s a technical topic or a non-technical one, I love creating content that is clear, engaging, and impactful.
View all posts by Vishalini Devarajan
Connect with me @




















Did you enjoy this article?