

Artificial Intelligence and Machine Learning Articles
How to Stream Claude Responses with the API
Claude API Pricing Breakdown: Token Costs and Tiers


Get In Touch For Details! Request More Information
The Hidden Logic Behind Neural Network Sigmoid Graphs
Jun 26, 2026 6 Min Read 342 Views
(Last Updated)
Artificial intelligence can appear surprisingly intuitive at times. A chatbot gives you an answer in milliseconds, a recommendation engine suggests your next likely purchase, and a fraud detection system flags suspicious activity instantly. At the heart of many of these systems is a mathematical concept that subtly played a role in shaping early machine learning: the sigmoid graph.
At first glance, the sigmoid graph is simple. It’s just a line in the shape of an “S” that goes from 0 to 1, curving smoothly between. But this curve introduced a fundamental idea into the world of neural networks: how to translate raw data into useful probabilities.
This article will explain the hidden logic behind neural network sigmoid activation functions, how they helped lay the foundation for deep learning, why they don’t perform well in many modern architectures, and why they are still useful today.
Table of contents
- TL;DR
- Why the Sigmoid Graph Changed AI
- Understanding the S-shaped Curve Logic
- The Mathematics Behind the Sigmoid Function
- Why Neural Networks Need Activation Functions
- How Sigmoid Functions Shape AI Predictions
- Understanding Gradient Interpretation in Sigmoid Graphs
- The Hidden Problem: Vanishing Gradients
- Sigmoid vs ReLU in Modern Deep Learning
- Real World Applications of Sigmoid Graphs
- Medical Diagnosis Systems
- Spam Detection
- Fraud Detection
- Recommendation Systems
- Sentiment Analysis
- Practical Python Example of a Sigmoid Graph
- Conclusion
- FAQs
- What is a sigmoid graph in machine learning?
- Why is the sigmoid function important in neural networks?
- What is the output range of the sigmoid function?
- What is the vanishing gradient problem in sigmoid functions?
- Is sigmoid still used in modern deep learning?
- What is the difference between sigmoid and ReLU?
TL;DR
- The sigmoid curve is a mathematical curve that resembles an “S” in machine learning and neural networks.
- It can transform any input number into an output between 0 and 1, allowing models to predict probabilities.
- The sigmoid graph introduced the concept of non-linear learning to neural networks.
- The sigmoid graph helps AI systems perform binary classification, confidence scores, and predict probabilities.
- While ReLU has mostly taken over in deep learning architectures, sigmoid functions are still prevalent in output layers of neural networks.
- An understanding of sigmoid graphs will lead to a deeper understanding of gradient flow, backpropagation, and vanishing gradients.
What is a Sigmoid Graph?
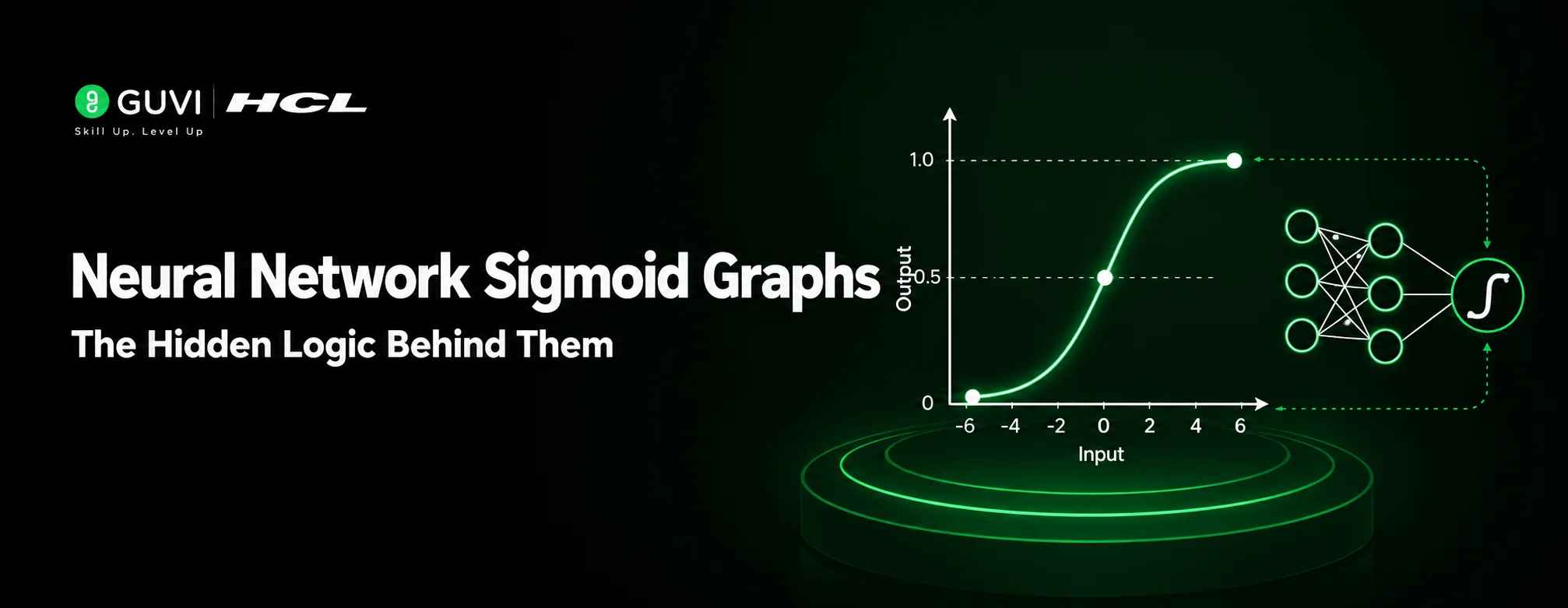
A sigmoid graph is an S-shaped mathematical curve produced by the sigmoid function in machine learning and deep learning. It transforms any real-valued numerical input into an output between 0 and 1, making it highly useful for probability prediction and binary classification tasks. The smooth, continuous shape of the sigmoid graph also helps neural networks model non-linear relationships in data.
Why the Sigmoid Graph Changed AI
Before the advent of activation functions, neural networks weren’t able to learn intricate relationships effectively. Even by adding many layers of neurons, the system essentially functioned as a linear equation, limiting its capacity to accurately process language, images, human behavior, or any complex pattern recognition.
The introduction of the sigmoid graph enabled non-linear learning. Instead of treating every single change to the inputs as equally important, the sigmoid function created a way for inputs to affect outputs gradually. This allowed neural networks to learn complex relationships rather than adhering to rigid, binary outcomes.
The sigmoid curve itself wasn’t as groundbreaking as the concept of turning probabilities into more human-understandable outputs. Rather than generating a raw, uninterpretable number, a neural network could now indicate how “likely” something was by stating that it was “90% probable.”
This transformation made the sigmoid graph crucial for early deep learning models, logistic regression models, and a wide range of binary classification problems.
Understanding the S-shaped Curve Logic
The sigmoid graph exhibits a unique and consistent pattern of behavior. Inputs close to 0 produce noticeable output changes, whereas extremely large positive or negative inputs produce very little change in the output. This characteristic gives the curve its S-shape because the output gradually approaches values it can never fully reach.
- Extremely negative values approach 0.
- Central values between -5 and +5 are highly sensitive.
- Extremely positive values approach 1.
The output can never be less than 0 or greater than 1. This behavior is valuable in AI because probabilities naturally exist within the same range. For example, in spam detection, a sigmoid graph can convert predictions into probability scores like 90% spam likelihood or 10% spam likelihood. This makes machine learning predictions easier to interpret and more practical in real-world applications.
The Mathematics Behind the Sigmoid Function
The sigmoid function is commonly written as the following equation:
σ(x)=1+e−x1
Although this equation might initially seem complicated, the mathematical logic behind it is quite clever. The exponent essentially takes very large or very small inputs and compresses them into a reasonable range of 0 to 1, keeping all outputs within these limits and enabling stable prediction behavior.
Some properties that make this function useful in AI:
- It’s smooth and continuous.
- It’s differentiable, a crucial property for AI to train itself, as explained in the next section.
- Its output range is suitable for probability outputs.
- It’s symmetric on either side of the zero-crossing point, meaning the magnitude of changes at +x is the same as changes at -x.
Sigmoid was implemented in neural networks largely because of differentiation, which plays a major role in how neural networks are trained. Without differentiation, performing gradient descent would not be possible.

Why Neural Networks Need Activation Functions
Without activation functions, a neural network is essentially a linear multiple stacked linear equation. The network will only be able to make decisions if the result it gets falls into specific, pre-defined categories, which makes it incapable of learning patterns within speech, faces, sentiments, or anything really complex.
The activation function introduces decision-making capability to each neuron in the network. The sigmoid was the first activation function widely accepted because it allowed neurons to activate more gradually than an on-off switch or, in other words, to behave more like a dimmer switch than an on/off light switch.
To understand how activation functions fit into complete neural network architectures, reading Understanding Neural Networks and Their Components can help connect sigmoid behavior with layers, weights, and backpropagation.
How Sigmoid Functions Shape AI Predictions
The sigmoid function helps AI systems interpret probability from numerical inputs. This is important in machine learning tasks that rely on prediction and confidence scoring.
For example, AI models use sigmoid functions to predict spam emails, fraudulent transactions, disease probability, or positive and negative reviews. The function converts prediction scores into values between 0 and 1, representing low or high confidence levels.
These probability-based outputs make sigmoid functions highly useful in binary classification tasks. Even today, sigmoid functions are commonly used in neural network output layers for real-world AI predictions.
Beginners interested in understanding how sigmoid functions work in probability prediction can also explore Sigmoid Function in Binary Classification & Neural Networks to understand how neural networks convert raw outputs into confidence scores.
Understanding Gradient Interpretation in Sigmoid Graphs
During the training of neural networks, the gradients, which represent the change in error associated with a weight change, are of great importance because they direct how the weights are adjusted during learning. The derivative for the sigmoid is as follows:
σ(x)(1−σ(x))
This shows that while training, for values near 0 on the sigmoid graph, the gradients are strong, meaning that the network learns better because the weights adjust at a quicker rate. Conversely, at either end of the sigmoid graph, the gradients are very small, which is an indicator of how slowly the network learns.
Because of this, the middle portion of the sigmoid graph is sometimes referred to as the “active learning zone,” and gradient interpretation is extremely important for machine learning and deep learning model training.
The Hidden Problem: Vanishing Gradients
The sigmoid graph proved to be a problem solver for many early AI problems, but at the same time, it added one major problem. That problem is called the vanishing gradient problem.
When your inputs are either extremely positive or extremely negative, the sigmoid output moves towards its saturation values near 0 or 1. At this point, the gradient is infinitesimally small.
Tiny gradients create a serious chain reaction:
- Learning in earlier layers becomes ineffective.
- Weight updates become extremely small.
- Deep neural networks begin training very slowly.
- Overall model performance starts to stagnate.
When neural networks became deeper, this problem started to become significant. Early researchers realized that sigmoid works fine on shallower architectures, but it had severe issues when networks became very deep, and the gradient weakened as it traveled back from layer to layer. Ironically, the same smoothing property that makes the sigmoid function work well on early AI problems becomes its main issue when neural networks go deeper.
Since sigmoid functions are closely connected to gradient flow issues, learning about the Vanishing Gradient Problem in Deep Learning Explained can help you understand why modern deep neural networks have moved toward newer activation functions.
Sigmoid vs ReLU in Modern Deep Learning
As deep learning continued to develop, researchers were looking for faster and more stable activation functions. This eventually led to the emergence of the ReLU activation function, which is an abbreviation of Rectified Linear Unit. Unlike sigmoid, it does not compress the output of a neuron into a fixed range. Instead, it lets any positive values pass through directly.
What are the differences and significance between these two functions?
- ReLU trains faster in deep networks.
- ReLU reduces the vanishing gradient problem.
- Sigmoid provides probability-friendly outputs.
- Sigmoid is superior for binary prediction layers.
That is why modern neural networks often combine multiple activation functions. For instance, one common network design used today would employ ReLU activation in hidden layers, but a sigmoid activation in the final output layer of a network architecture. Hence, even though ReLU has become dominant in most deep learning architectures, sigmoid is still deeply connected to prediction based on probabilities.
Real World Applications of Sigmoid Graphs
The sigmoid graph is being widely used in many areas of artificial intelligence.
1. Medical Diagnosis Systems
These AI models can predict the probability that a patient has a certain illness. Instead of saying a patient definitively has a disease, the model gives a probability, which will determine if a patient has the disease.
2. Spam Detection
An AI will look at the probabilities that an email belongs in a spam folder and place the email in the spam folder if the probabilities exceed a certain value.
3. Fraud Detection
Bank systems will utilize a sigmoid graph to find the probability of fraudulent transactions occurring in real time.
4. Recommendation Systems
For example, streaming services and e-commerce applications will use sigmoid to predict the probability of users clicking to watch a particular video or buy a certain product.
5. Sentiment Analysis
NLP systems can analyze written texts such as reviews or customer feedback and determine if the text is positive or negative.
Practical Python Example of a Sigmoid Graph
Visualizing the sigmoid function makes the concept easier to understand.
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-10, 10, 100)
y = 1 / (1 + np.exp(-x))
plt.plot(x, y)
plt.title(“Sigmoid Graph”)
plt.xlabel(“Input”)
plt.ylabel(“Output”)
plt.grid(True)
plt.show()
As observed in the code above, the sigmoid function generates a classic S-shaped curve when graphed against input values from negative 10 to positive 10. When the inputs increase to a higher value, the sigmoid function value smoothly tends towards 1, while decreasing values bring the sigmoid function value closer to 0.
Readers who want practical exposure to activation functions in real AI models can also explore Build a Neural Network Using TensorFlow: A Practical Guide to see how sigmoid and ReLU are implemented in deep learning workflows.
This smoothly changing aspect of the sigmoid function allows it to be efficiently applied to machine learning prediction models. For further understanding of the calculation of the sigmoid, an AI ebook on mathematical foundations would allow a connection to other concepts like backpropagation and gradient descent more smoothly.
The sigmoid activation function was inspired by the behavior of biological neurons. In the human brain, neurons do not simply switch on or off instantly; their activation strength changes gradually depending on incoming signals. The sigmoid function mathematically imitates this behavior by smoothly mapping input values into a range between 0 and 1, making it one of the earliest and most influential activation functions used in artificial neural networks.
Why Sigmoid Still Matters Today
Many beginners would assume that sigmoid functions have become outdated due to the popularization of ReLU. Such an assumption would be factually incorrect. Sigmoid functions continue to remain vital in machine learning tasks involving probabilities and classification of data.
When the task is about asking how probable an event will occur, what the certainty level is, or if a certain prediction would cross the designated threshold for implementation, sigmoid plays a crucial role. Novel activation functions that resemble sigmoid functions are also being explored. Thus, modern AI often improves on foundational ideas instead of replacing them entirely.
If you want practical experience working with activation functions, neural networks, and deep learning models, HCL GUVI’s AI and ML Course can help you understand how concepts like sigmoid, backpropagation, and gradient descent are implemented using frameworks such as TensorFlow and PyTorch through hands-on projects.
Conclusion
The sigmoid graph helped shape the foundation of modern neural networks by enabling non-linear learning and probability-based predictions. Even with newer activation functions dominating deep learning, the sigmoid remains important in binary classification and AI prediction systems.
FAQs
1. What is a sigmoid graph in machine learning?
A sigmoid graph is an S-shaped mathematical curve that converts numerical inputs into outputs between 0 and 1. It is widely used in machine learning for probability prediction and binary classification tasks.
2. Why is the sigmoid function important in neural networks?
The sigmoid function introduces nonlinearity into neural networks, allowing them to learn complex relationships instead of behaving like simple linear models.
3. What is the output range of the sigmoid function?
The sigmoid function always produces outputs between 0 and 1, making it useful for confidence scoring and probability interpretation.
4. What is the vanishing gradient problem in sigmoid functions?
The vanishing gradient problem occurs when sigmoid outputs saturate near 0 or 1, causing gradients to become extremely small and slowing down neural network training.
5. Is sigmoid still used in modern deep learning?
Yes. Although ReLU is more common in hidden layers, sigmoid functions are still widely used in output layers for binary classification and probability prediction tasks.
6. What is the difference between sigmoid and ReLU?
Sigmoid compresses outputs between 0 and 1, while ReLU allows positive values to pass through directly. ReLU generally trains faster in deep networks, but sigmoid remains valuable for probability-based predictions.
Success Stories

About the Author
Vishalini Devarajan
An Aerospace Engineer turned content writer, I focus on making complex concepts easy to understand through well-structured, reader-friendly blogs. Whether it’s a technical topic or a non-technical one, I love creating content that is clear, engaging, and impactful.
View all posts by Vishalini Devarajan
Connect with me @





















Did you enjoy this article?