

Big Data Articles
Role of Data Science in Big Data Analytics


Get In Touch For Details! Request More Information
Apache Kafka: Architecture, Working, Features & Use Cases Explained
May 26, 2026 4 Min Read 325 Views
(Last Updated)
In today’s data-driven world, Apache Kafka has become one of the most widely used technologies for handling massive amounts of real-time data generated by modern applications. From online transactions to live notifications, businesses rely on systems that can efficiently process continuous data streams.
As companies continue to build faster, more scalable applications, technologies like Apache Kafka are playing a major role in modern data processing and event-driven architectures across industries.
Table of contents
- TL;DR Summary
- What is Apache Kafka?
- For Example:
- Apache Kafka Architecture
- Key Components of Apache Kafka
- Producers
- Consumers
- Topics
- Partitions
- Brokers
- Kafka Cluster
- How Apache Kafka Works
- Features of Apache Kafka
- a. High Throughput
- b. Scalability
- c. Fault Tolerance
- d. Real-Time Processing
- e. Durability
- Benefits of Using Apache Kafka
- a. Fast Data Processing
- b. Easy Integration
- c. Reliable Data Handling
- d. Cost Efficient
- e. Better System Performance
- Conclusion
- FAQs
- Why is Apache Kafka popular for real-time data processing?
- Which companies commonly use Apache Kafka?
- What makes Apache Kafka different from traditional messaging systems?
- Can Apache Kafka handle large-scale applications?
- Why do developers prefer Apache Kafka for data streaming?
- What type of data can Apache Kafka process?
TL;DR Summary
- Get a clear understanding of what Apache Kafka is and why businesses use it for real-time data streaming.
- Learn the architecture and key components of Apache Kafka in a simple and easy-to-follow way.
- Understand how Apache Kafka works behind the scenes to manage and process large amounts of data efficiently.
- Explore the features, benefits, and real-world use cases of Apache Kafka across different industries.
Apache Kafka was created in 2011 by Jay Kreps, Neha Narkhede, and Jun Rao at LinkedIn to manage large-scale real-time data streams.
What is Apache Kafka?
Apache Kafka is a platform for collecting, storing, and transferring large amounts of real-time data between applications and systems. It helps businesses move data quickly and continuously, making it useful for notifications, online payments, user activity tracking, messaging systems, and live data processing in modern applications.
For Example:
When you place an order online, receive a notification, or watch live updates in an app, Apache Kafka helps move that data smoothly from one system to another without delays.
Ready to build real-world event-driven apps like a pro? Join HCL GUVI’s Setup Kafka Consumer and Producer in Java with Spring Boot and start creating scalable microservices with Apache Kafka, Spring Boot, and hands-on projects that actually level up your backend skills.
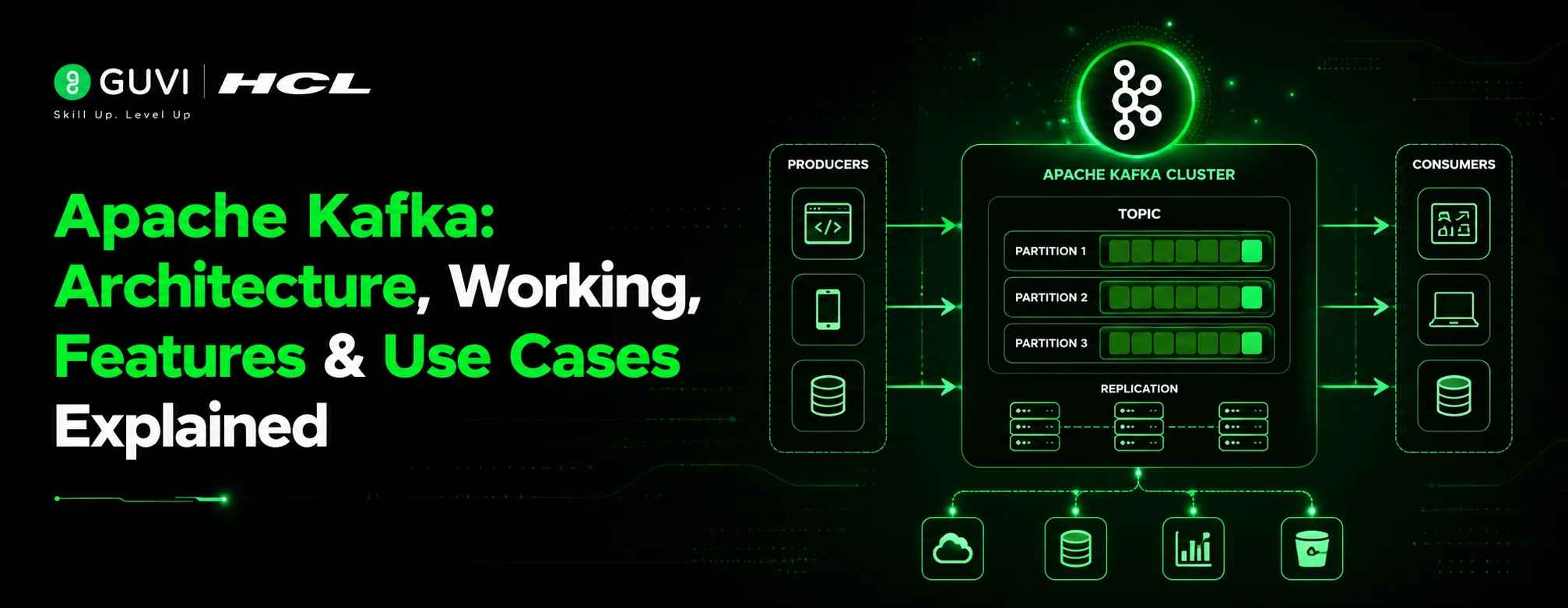
Apache Kafka Architecture
The Apache Kafka architecture functions as a smart data delivery system. In Kafka, Producers are the applications that send data, such as websites, mobile apps, or payment systems.
This data is sent to the Kafka Cluster, the primary system responsible for storing and managing it.
In the Kafka Cluster, data is organised into Topics, and each Topic is divided into smaller parts called Partitions to handle large amounts of data efficiently.
The cluster contains multiple Brokers, servers that store and distribute data.
Finally, Consumers are the applications or services that receive and use this data for analytics, notifications, monitoring, and real-time updates.
Key Components of Apache Kafka
These are the 6 key components of Apache Kafka:
1. Producers
Producers are the starting point of Apache Kafka. They are applications or systems that send data (messages/events) into Kafka. Think of them as the “data senders” that capture real-world activity, such as clicks, payments, or orders, and push it into Kafka so it can be used later.
Without Producers, there is no data flow in Kafka. They ensure that every important event from apps, websites, or services is collected and delivered to the system in real time.
2. Consumers
Consumers are the “data users” in Apache Kafka. They read and process the data that producers send into Kafka. These can include applications such as analytics tools, dashboards, or notification systems that require real-time information.
Consumers ensure that the data stored in Kafka is used for decision-making, generating insights, or taking actions such as sending alerts, updating dashboards, or triggering workflows.

3. Topics
A Topic is like a folder or category where Kafka stores data. Every piece of data sent by producers is assigned to a specific topic based on its type, such as orders, payments, or user activity.
Topics help organise data so it is clean, structured, and easy to manage, even when millions of messages are flowing every second.
4. Partitions
Partitions are smaller parts inside a topic. They split the large dataset into chunks so Kafka can handle it more quickly and efficiently. Each partition stores data in order, like a timeline of events.
This design enables Kafka to process large volumes of data in parallel, making it extremely fast and scalable.
5. Brokers
Brokers are the servers that actually store and manage Kafka data. They take data from producers, store it safely in topics and partitions, and serve it to consumers when needed.
In simple terms, brokers are the backbone of Kafka, making sure data is always available, balanced, and reliable.
6. Kafka Cluster
A Kafka Cluster is a group of multiple brokers working together. This setup ensures that Kafka is highly scalable, fault-tolerant, and always available, even if a single server fails.
It is the complete system that keeps everything connected, balanced, and running smoothly without data loss or downtime.
How Apache Kafka Works
Apache Kafka processing starts when a Producer sends data (called events/messages) to Kafka. This data is first sent to a specific Topic, which serves as a category for storing similar types of data.
Once the data reaches the topic, Kafka automatically splits it into Partitions, so that the data can be handled in smaller parts and processed faster.
These partitions are then distributed across multiple Brokers within a Kafka Cluster, ensuring the data is safely stored and managed in a balanced way.
Once the data is stored, the next step is for a Consumer to connect to Kafka and start reading from the same Topics and Partitions. Consumers can read data in real time or process it later, depending on the requirement.
While this happens, Kafka continues to track what has been read and what is pending, ensuring that no data is lost or duplicated.
In this way, Apache Kafka creates a seamless flow in which data is continuously produced, stored, distributed, and consumed in real time, making the entire system fast, reliable, and scalable.
Features of Apache Kafka
These are the following key features of Apache Kafka that make it a powerful distributed streaming platform:
a. High Throughput
Kafka can handle a very large volume of data simultaneously without slowing down, making it highly suitable for real-time streaming applications.
b. Scalability
It can easily scale by adding more servers or clusters, allowing it to handle increasing data load and traffic without requiring major system changes.
c. Fault Tolerance
Even if some system components fail, Kafka still keeps the data safe and consistent, and continues running without interrupting the workflow.
d. Real-Time Processing
Kafka allows data to be processed instantly as it arrives, enabling applications to make faster decisions and deliver quicker responses.
e. Durability
Data in Kafka is retained for a configured period, so it can be replayed or accessed later for processing or analysis.
Benefits of Using Apache Kafka
The following are the benefits of Apache Kafka:
a. Fast Data Processing
Kafka helps with the rapid processing of large data streams, enabling systems to respond in real time without delay.
b. Easy Integration
It easily integrates with various systems and applications, ensuring smooth data flow across multiple platforms and services.
c. Reliable Data Handling
Kafka ensures no data loss by safely storing messages and delivering them consistently and reliably.
d. Cost Efficient
It reduces the need for complex data pipelines, helping organisations save infrastructure and maintenance costs.
e. Better System Performance
By efficiently handling messaging, Kafka reduces system load, improving the overall speed and performance of applications.
Data is running the world quietly in the background, and the people who understand it are building the future. Join HCL GUVI’s Introduction to Data Engineering and Big Data Course and start learning how real data pipelines, Big Data systems, and modern data workflows actually work in today’s tech industry.
Conclusion
In conclusion, Apache Kafka is widely used for handling real-time data in modern applications. It helps in fast data processing, smooth communication between systems, and reliable data delivery even under heavy load. This makes it an important tool for building scalable and efficient data-driven solutions.
FAQs
Why is Apache Kafka popular for real-time data processing?
Apache Kafka can handle large volumes of data with very low latency.
Which companies commonly use Apache Kafka?
Many tech, banking, e-commerce, and streaming companies use Apache Kafka.
What makes Apache Kafka different from traditional messaging systems?
Apache Kafka is built for high-speed data streaming and scalability.
Can Apache Kafka handle large-scale applications?
It is designed to efficiently manage millions of messages.
Why do developers prefer Apache Kafka for data streaming?
Developers use it for reliability, fast performance, and easy integration.
What type of data can Apache Kafka process?
It can process logs, transactions, website activity, and real-time event data.
Success Stories




























Did you enjoy this article?