



Understanding Scraping Website Data
Scraping Product Names from ConsumerReports Website
NOTE: This tutorial is just for educational purpose and we request the reader to not use the code to carry out harm to the website in any form whatsoever.
In this tutorial we will learn how to actually scrape data off any website. The website from which we will get the data is ConsumerReports website. We will be requesting data from this URL and then collect the product names list from it.
Let the scraping begin...
importing bs4, requests and fake_useragent modules
import bs4 import requests from fake_useragent import UserAgent
initializing the UserAgent object
user_agent = UserAgent() url = "https://www.consumerreports.org/cro/a-to-z-index/products/index.htm"
getting the reponse from the page using get method of requests module
page = requests.get(url, headers={"user-agent": user_agent.chrome})
storing the content of the page in a variable
html = page.content
By this step, we already have the complete source code for the webpage stored in our variable `html`. Now let's create BeautifulSoup object. You can even try and run the `prettify` method.
```pythoncreating BeautifulSoup object
soup = bs4.BeautifulSoup(html, "html.parser")
We have also created the BeautifulSoup object, now what? How do we know which tag to find and extract from the HTML code. Should we search HTML code for it? No way!
Remember in the first tutorial of this series when we introduced the term web scraping, we did share a technique with you, where we could use the **Chrome browser's Developer tool** to find the HTML code for any webpage element.(other browsers like Firefox etc too have there own developer tools which can also be used.)
Open the Developer Tools(in chrome browser) by pressing **F12** key if you are using Windows and **Option + Command + I** if you are a Mac user.
Click on the top-left corner button:
And then hover your mouse cursor on the Product list entries to find their HTML tags:
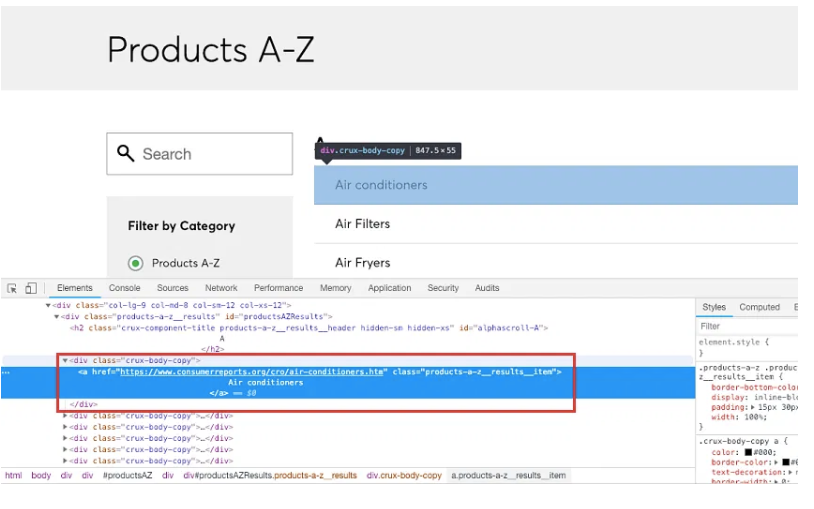
See, how simple it was. And with this we have successfully scraped data from a website.





























































