



Understanding the Dataset
Lesson 3: Understanding the Dataset
After loading the dataset, the next step is to understand its structure and contents. This step helps confirm that the data has been loaded correctly and gives a clear overview of what kind of information each column represents.
We begin by viewing the first few rows of the dataset. This provides a quick snapshot of the sales records, including order details, product information, and sales values.
Code to view sample rows:
df.head()
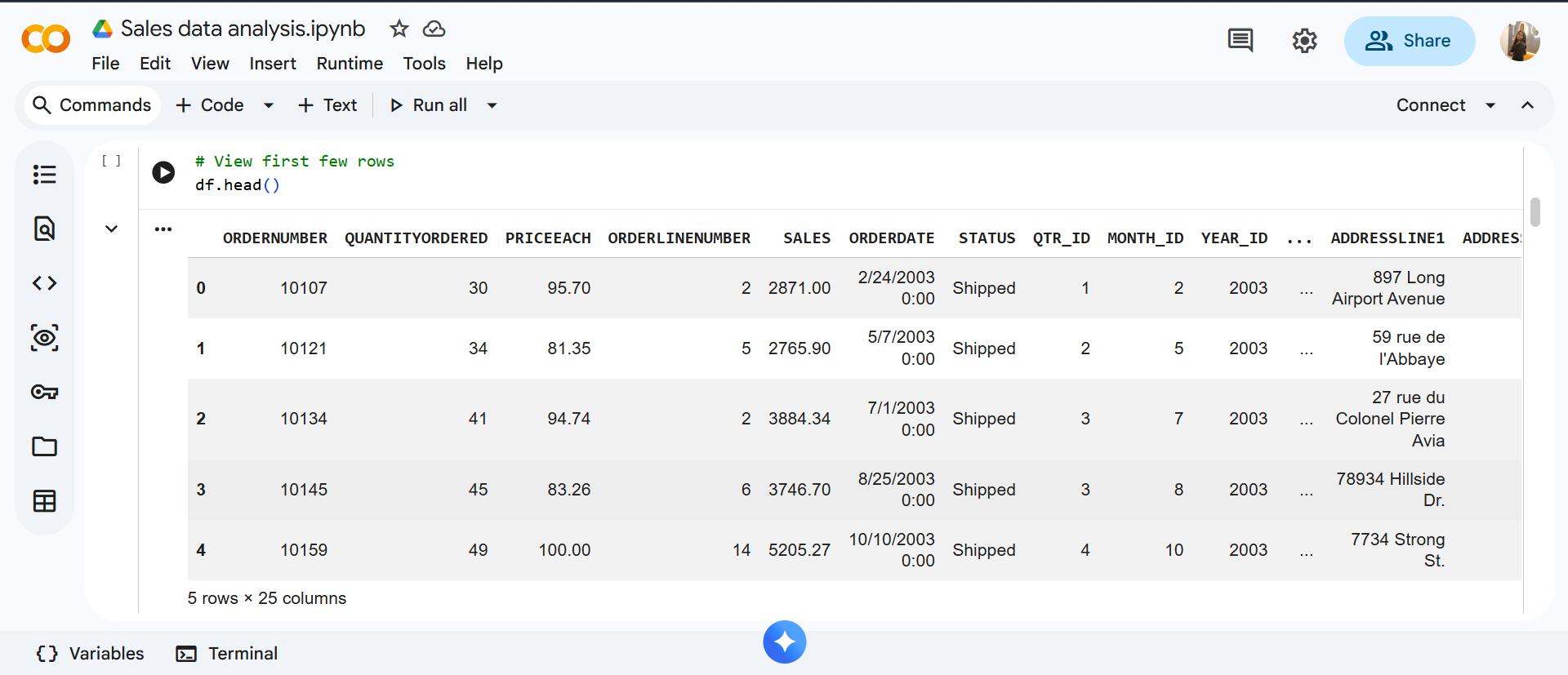
The output shows a preview of the dataset, confirming that each row represents a sales transaction with details related to orders, products, customers, and sales values.
Next, we check the shape of the dataset to understand how many rows and columns are present.
Code to check dataset size:
df.shape
From the above output we can understand that the dataset contains 2,823 rows and 25 columns, indicating a moderately sized dataset suitable for sales analysis and trend identification.
Finally, we examine detailed information about the dataset, such as column names, data types, and the presence of missing values.
Code to inspect dataset structure:
df.info()
Here we can see that the dataset consists of both numerical and categorical data types, with a few columns containing missing values, which requires cleaning before further analysis.
The above steps help us build familiarity with the dataset and prepare it for data cleaning and preparation in the next lesson.






























































